Temps réel : Comment bien espionner vos voisins - Parabole acoustique et filtre NLMS
Le débruitage audio est une fonctionnalité clé dans de nombreux dispositifs modernes, des écouteurs intelligents aux systèmes de communication avancés. Pourtant je n'ai trouvé aucune ressource détaillant l'implémentation de l'algorithme NLMS (Normalized Least Mean Squares) sur l'ESP32, un microcontrôleur pourtant bien adapté au traitement audio en temps réel. Dans cet article, je vous propose de découvrir un projet de parabole acoustique équipée de deux micros MEMS et d’un décodeur I2S, reliés à un ESP32 via ses deux ports I2S. En plus de partager le code pour implémenter le filtre NLMS, j'inclus les plans CAO pour que vous puissiez imprimer en 3D les pièces nécessaires à la construction de votre propre dispositif. Je décrirai également, de manière succincte, le fonctionnement des filtres FIR et des filtres adaptatifs comme le NLMS. Ce projet est conçu comme une base matérielle et logicielle qui pourra être étendue à l’avenir pour explorer différents types de débruitage. Toutes les expériences futures seront mises à disposition sur mon GitHub. Prêt à découvrir ce que vos voisins racontent sur vous ? Suivez-moi dans cette aventure acoustique et technique !
Bertrand Selva
12/18/20247 min read


Voici une solution fonctionnelle d’écoute longue distance, combinant deux stratégies :
Augmentation du gain avec une parabole acoustique : un micro MEMS est placé au foyer de la parabole pour capter le signal cible. J’utilise des micros MEMS NMLP441 pour leur sensibilité de -26 dB, mais aussi parce qu’ils sont moins sensibles au bruit que les micros analogiques et qu’on récupère un signal déjà numérisé.
Traitement du signal pour améliorer le rapport signal sur bruit (SNR) : deux micros MEMS sont utilisés dans le dispositif. Le premier, au foyer de la parabole, capte signal et bruit. Le second, à 18 cm du premier, capte principalement le bruit ambiant. L’idée est de traiter ces deux signaux pour supprimer le bruit et obtenir un signal clair.
Retrouvez sur le dépot github le code avec le traitement du signal, les gcode des pièces à imprimer pour la fabrication, la liste des composants nécessaires, etc :
https://github.com/Bertrand-selvasystems/acoustic-parabola-nlms-dsp-esp32
Ce dispositif expérimental se prête bien aux essais. Voici un schéma qui récapitule les différents composants utilisés, avec les deux micros MEMS INMP441, le décodeur audio UDA1334A et l'ESP32S3 disposant d'une LED intégrée WS2812 :
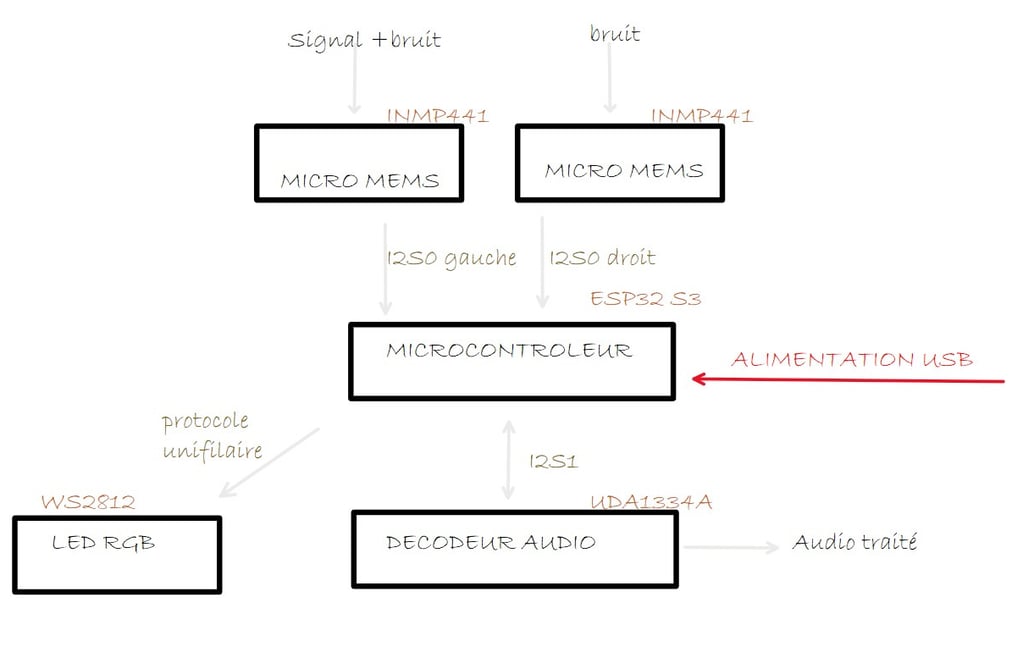
Pourquoi l’ESP32 ?
Pour réaliser un tel dispositif d’écoute, il faut un microcontrôleur capable de gérer efficacement l’audio numérique tout en restant abordable. C’est là que l’ESP32 s’impose comme une solution parfaite. C’est assez surprenant pour un microcontrôleur dans cette gamme de prix, mais il dispose de caractéristiques qui le rendent particulièrement intéressant pour ce type de projet :
Deux ports I2S, qui permettent de connecter des périphériques audio numériques.
Des fonctions DSP intégrées permettant de réaliser des filtres FIR, des FFT, etc.
Une puissance de calcul suffisante pour envisager des traitements audio avancés en temps réel.
Et pourtant, l’utilisation de ces fonctions DSP sur ESP32 pour faire du traitement du signal semble peu répandue. C’est pourquoi, en explorant ce sujet, je vais partager chaque solution que j’implémente sur GitHub. L’objectif est de fournir une plateforme accessible et documentée pour expérimenter sur ce sujet.
La structure du programme : temps réel et FreeRTOS
Il est plus efficace de laisser le pipeline de traitement complet pour le dépôt, incluant l’acquisition des données, car cela permet de réinvestir plus facilement le code.
Le code est organisé de manière modulaire, l’acquisition est dans micros.c, le traitement dans filtre.c, etc. Des queues FreeRtos permettent de transmettre les adresses des pointeurs sur les blocs à traiter, à transmettre entre les différentes tasks déclarés dans le main.
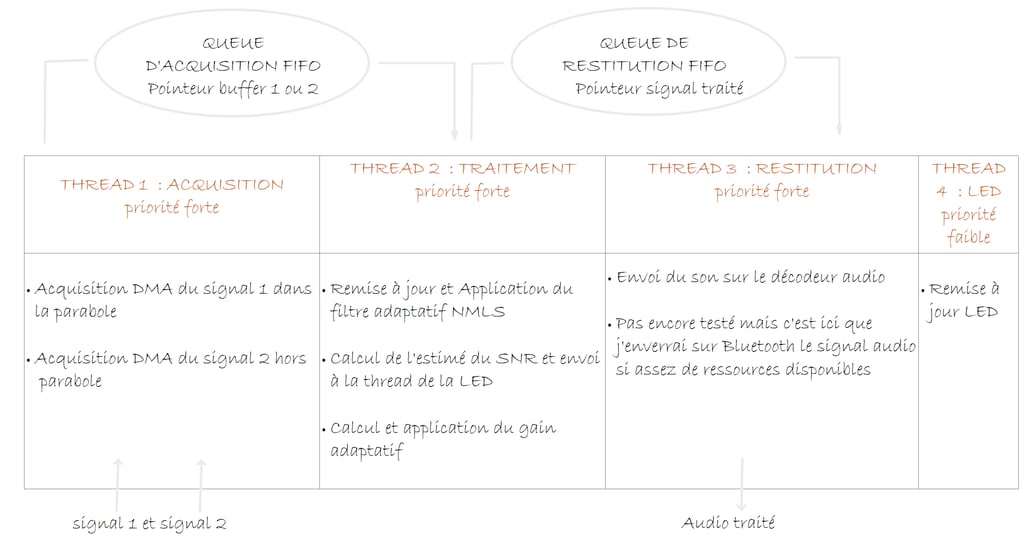
J’utilise un double buffer pour l’acquisition. Il n’y a pas de buffer pour la restitution. Cela fonctionne bien car le temps de traitement est quasi constant.
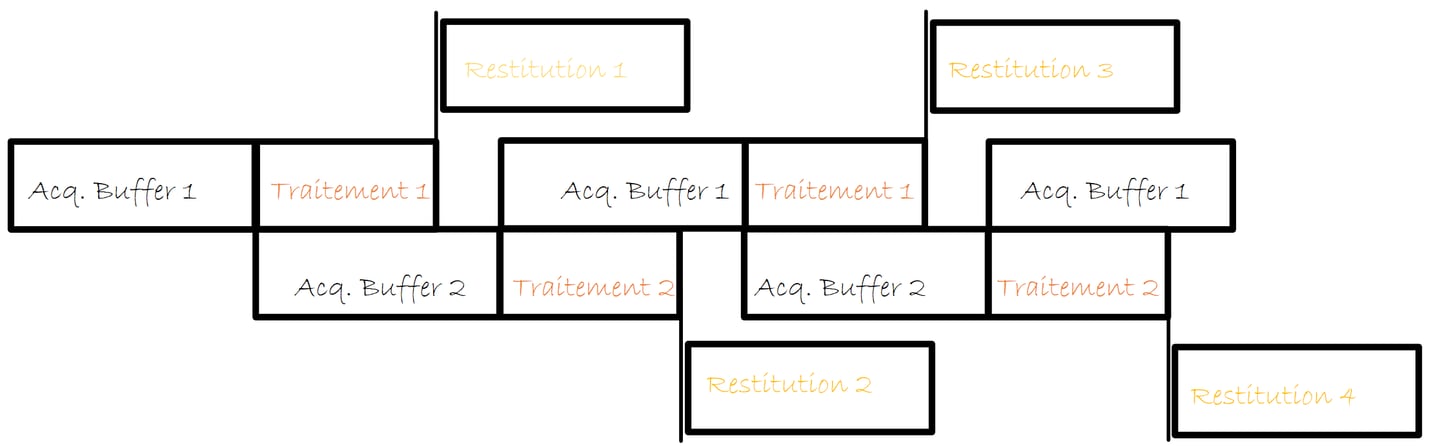
Ce retard initial d’un bloc de données se poursuit par-delà la phase initiale d’alimentation du pipeline de traitement. 1 buffer de 128 échantillons à 48 Khz, ça fait un retard de 2.5 ms. Ce n’est donc pas une gêne pour nous.
Les solutions envisagées pour le traitement du signal
Ce qui est intéressant avec ce dispositif, c'est qu'il offre une plateforme de test intéressante pour essayer différentes solutions de débruitage. Dans la suite, je propose plusieurs solutions. Celle qui est implémenté dans le code disponible ici est la solution 2 ! (car elles sont classées par ordre croissant de coût en terme de temps d’exécution).
Solution 1 : Filtrage à retard dynamique
Principe : Si on fait l’hypothèse que le bruit capté par les deux micros est similaire mais décalé temporellement à cause de la différence de marche d’onde, on peut corriger ce décalage pour isoler le signal. Voici les étapes principales :
Mesurer le décalage temporel :
Calculer la fonction de corrélation entre les deux signaux pour identifier le décalage temporel.
Identifier le pic de la fonction de corrélation pour déterminer ce décalage et utiliser l’interpolation autour du pic pour améliorer la résolution et permettre l’identification du décalage temporel avec une résolution sub-pas.
Décaler un des deux signaux
Décaler du nombre de pas entierCréer et appliquer un filtre FIR 1 pour le décalage temporel sub-pas restant.
Soustraire les signaux : la soustraction des deux signaux permet d'enlever le bruit du signal issu de la parabole selon nos hypothèses
Appliquer un filter FIR 2 : Appliquer un filtre passe bande réglée pour la voie humaine
Appliquer un gain dynamique et gestion de la saturation.
Inconvénients et limites :
Cette méthode est relativement simple à implémenter (il faut quand même gérer les débordements du bloc en cours de traitement en faisant rentrer plusieurs blocs dans le pipeline de traitement, avec à la clé une occupation mémoire accrue et une latence supplémentaire), mais elle montre ses limites dans des environnements où le bruit varie rapidement ou est imprévisible. La précision dépend fortement de la qualité du calcul de corrélation, il faut une résolution inférieure au pas, en particulier pour soustraire les hautes fréquences. Mais cette solution permet de libérer du temps de calcul pour le reste du programme. Je finalise mon programme et je la laisserai accessible sur github sous peu.
Solution 2 : Filtrage adaptatif : NLMS
Principe : Le filtre NLMS (Normalized Least Mean Square) utilise un algorithme adaptatif qui ajuste dynamiquement les coefficients d’un filtre FIR pour minimiser l’erreur quadratique entre les deux signaux. C’est une méthode très largement utilisée pour la réduction du bruit dans des contextes similaires à celui présenté ici. Voici les étapes principales :
Acquérir le signal et normaliser les signaux entrants
Calculer les coefficients adaptatifs : Utiliser un algorithme NLMS pour ajuster les coefficients du filtre FIR de manière itérative afin de minimiser l’écart quadratique moyen entre le bruit capté par le second micro et celui présent dans le signal principal. Cette minimisation repose sur l'idée que l'erreur calculée, c'est-à-dire la différence entre le signal de sortie filtré et le signal de référence, doit être réduite en ajustant les coefficients pour mieux modéliser le bruit capté, tout en normalisant l’adaptation pour éviter une convergence instable due à des variations d’amplitude dans le signal. Je détaille un peu plus le fonctionnement du filtre dans la dernière partie.
Appliquer le filtre au signal : Extraire le bruit et récupérer un signal filtré dynamique.
Gérer la dénormalisation et le gain dynamique
Inconvénients et limites :
Cette solution est un peu plus complexe à implémenter. Le filtre NLMS exige des réglages pour le pas d’adaptation, qui influe sur la vitesse et la qualité de la convergence. De mauvais paramètres peuvent conduire à des résultats médiocres ou instables. Bien que l’ESP32 ait suffisamment de puissance pour gérer ce traitement, cette méthode consomme plus de ressources que la solution à retard dynamique. Elle peut aussi introduire des artefacts sonores si le bruit évolue trop rapidement. Cette solution est particulièrement utile dans des environnements plus dynamiques, comme capter une conversation dans un café animé.
Vous trouverez le dépôt associé à cette solution sur : https://github.com/Bertrand-selvasystems/acoustic-parabola-nlms-dsp-esp32
Les solutions 1 et 2 ne sont pas exclusives : il est possible, pour faciliter la convergence du filtre adaptatif, de recaler les signaux comme dans la solution 1 avant de les faire rentrer dans le filtre adaptatif même si le filtre NLMS permet de compenser les retards également par le jeu de la minimisation de l'erreur.
Solution 3 : Filtrage de Wiener
Le filtre de Wiener est une méthode de réduction de bruit qui travaille dans le domaine fréquentiel. Il repose sur une analyse des spectres de puissance du signal et du bruit pour concevoir une fonction de transfert optimisée. Cette fonction ajuste les composantes fréquentielles du signal afin d’atténuer le bruit tout en préservant le contenu utile.
En pratique, le signal est transformé en fréquence via une FFT (Fast Fourier Transform), où le filtre est appliqué en fonction des densités spectrales estimées du signal et du bruit. Après filtrage, une transformation inverse (IFFT) permet de revenir dans le domaine temporel avec un signal nettoyé.
Idéal pour les bruits stationnaires comme un ventilateur ou une climatisation, le filtre de Wiener est moins adapté aux bruits fluctuants. Sa mise en œuvre nécessite toutefois des ressources de calcul, ce qui peut limiter son utilisation en temps réel sur des systèmes embarqués.
Solution 4 : Réseau de neurones pour la suppression de bruit
Une approche innovante pour la suppression de bruit consiste à utiliser un réseau de neurones capable de séparer le signal utile du bruit. Contrairement aux filtres traditionnels, cette méthode ne repose pas sur des hypothèses de linéarité ou de stationnarité, ce qui lui permet de capturer des relations complexes entre le signal et le bruit. Le réseau est d'abord entraîné avec des exemples de données bruitées et non bruitées, afin de développer un modèle capable de distinguer les deux. Une fois entraîné, ce modèle peut être appliqué au signal capté pour produire une sortie filtrée.
Cependant, cette méthode présente des défis, notamment pour une implémentation sur un ESP32. Les contraintes en mémoire vive et en puissance de calcul limitent la profondeur et la complexité des réseaux utilisables, ce qui peut réduire l'efficacité du filtrage. Bien que je sois sceptique quant à la capacité d'un ESP32 à exécuter un réseau de neurones performant, cette approche mérite d’être explorée. Elle ressemble assez à ce que j'avais proposé ici pour le KWS : l'extraction de freatures ce fait à partir de spectrogrammes : https://selvasystems.net/deep-learning
Perspectives
Ce montage n’est pas seulement une solution pour écouter à longue distance pour espionner vos voisins : c’est aussi une excellente plateforme pour expérimenter différentes techniques de traitement du signal. Les capacités DSP de l’ESP32, souvent sous-exploitées, offrent un terrain de jeu vraiment intéressant (et il serait également possible de directement coder de nouvelles fonctions en utilisant les instructions SIMD (Single Instruction, Multiple Data), c’est très intéressant pour des applications exigeantes).
Je déposerai les codes et bibliothèques associés à chaque méthode sur GitHub au fur et à mesure de mes essais. Vos retours et idées seront les bienvenus !
Innovation
Systèmes embarqués, intelligence artificielle, deep learning, solutions sur mesure, efficacité, innovation, sécurité, fiabilité.
Contact
© 2025. All rights reserved.
© 2025. Tous droits réservés.