Mines, roches et ESP32 : une application de DeepLearning
Dans cet article nous montrons que L’ESP32 permet de réaliser des projets de Machine Learning embarqué : un réseau de neurones permet d’opérer la classification pour le jeu de données “Sonar” de l’UCI Machine Learning Repository (un jeu de données très utilisés pour apprendre le machine learning). Cet article présente les grandes étapes de la démarche : présentation du dataset, préparation des données, conception et entraînement du réseau de neurones sur Python avec PC. En conclusion nous montrons le résultat du déploiement sur l'ESP32 S3, avec la classification des différents échantillons. Le code spécifique d’intégration est disponible sur le dépôt GitHub https://github.com/Bertrand-selvasystems/DeepLearning_ESP32_S3.
Bertrand Selva
1/30/20257 min read


Introduction
Dans cet article nous montrons que L’ESP32 permet de réaliser des projets de Machine Learning embarqué : un réseau de neurones permet d’opérer la classification pour le jeu de données “Sonar” de l’UCI Machine Learning Repository (un jeu de données très utilisés pour apprendre le machine learning). Cet article présente les grandes étapes de la démarche : présentation du dataset, préparation des données, conception et entraînement du réseau de neurones sur Python avec PC. En conclusion nous montrons le résultat du déploiement sur l'ESP32 S3, avec la classification des différents échantillons. Le code spécifique d’intégration est disponible sur le dépôt GitHub https://github.com/Bertrand-selvasystems/DeepLearning_ESP32_S3.
Présentation du jeu de données Sonar
Le jeu de données Sonar (Connectionist Bench Sonar Mines vs. Rocks) provient du UCI Machine Learning Repository. Il contient 208 échantillons, chacun décrit par 60 caractéristiques numériques (certainement des spectres même si les unités ne sont pas renseignées). Les valeurs correspondent à l’intensité de signaux sonores à différentes fréquences, mesurés à l’aide d’un sonar. L’objectif est de distinguer des mines sous-marines de simples rochers. On trouve deux étiquettes possibles pour chaque échantillon : “R” (rock) ou “M” (mine).
Voici deux exemples de spectre, l’un associé à un échantillon « R », l’autre associé à un échantillon « M » :
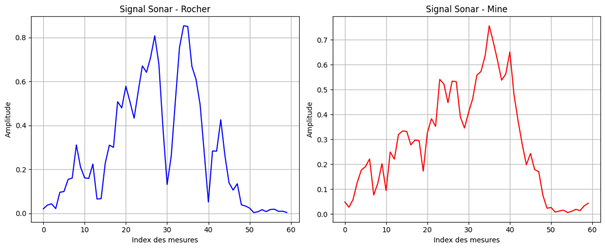
Ce dataset est apprécié pour plusieurs raisons. D’abord, sa taille relativement restreinte le rend adapté à des expériences avec des phases d’entrainement « rapides » (bien pour apprendre). Ensuite, c’est un problème de classification binaire, ce qui simplifie un peu la structure du réseau de neurones à déployer. Enfin, il est couramment utilisé pour évaluer et comparer différents algorithmes de classification, ce qui permet de situer la performance d’un modèle développé pour un microcontrôleur par rapport à d’autres approches.
Préparation des données
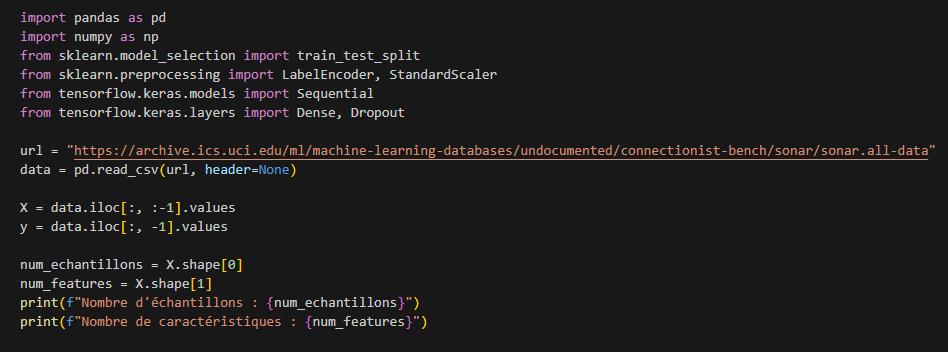
Pour travailler sur ces données, je suis parti d’un script en Python pour charger et analyser le dataset Sonar (il est disponible dans le répertoire model du dépôt github). J’utilise les librairies classiques Pandas et NumPy, ainsi que scikit-learn et TensorFlow Keras pour la partie Machine Learning. Voici d’abord un extrait de code qui montre comment charger le fichier CSV depuis l’URL officielle, séparer les caractéristiques (X) et les étiquettes (y), puis afficher le nombre d’échantillons et de caractéristiques :
Une fois ces données chargées, j’encode les étiquettes de type texte (“R”/“M”) en valeurs numériques (0/1) avec LabelEncoder. Enfin, je sépare le dataset en un ensemble d’entraînement et un ensemble de test, afin de pouvoir évaluer les performances réelles du modèle après son entraînement.
Conception et entraînement du réseau de neurones
J’utilise ici un réseau de neurones simple, construit avec Keras. L’approche consiste à définir un modèle Sequential dans lequel plusieurs couches denses (Dense) sont empilées, chacune suivie d’une activation non linéaire. Voici la déclaration du modèle :
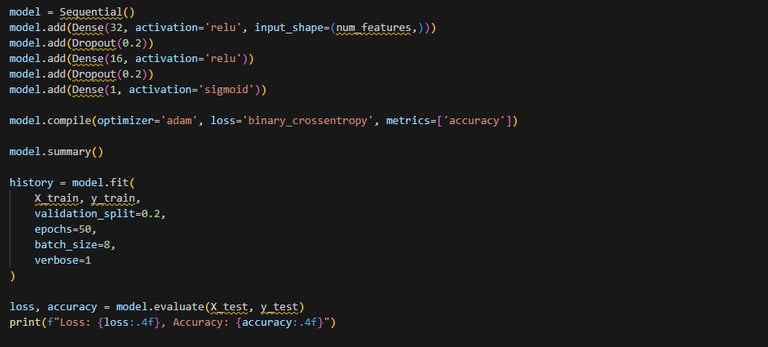
Le modèle est composé de trois couches denses de 32 neurones. la première couche reçoit les 60 caractéristiques en entrée. La couche de sortie est composée d'un seul neurone (activation “sigmoid”) pour une classification binaire. Les fonctions d’activation utilisées sont “ReLU” dans les couches cachées, et la fonction sigmoïde pour la sortie, ce qui est standard pour un problème de classification à deux classes.
Cette architecture assez simple peut déjà produire de bons résultats sur le dataset Sonar, notamment parce que le nombre d’exemples (208) reste modeste. J’utilise l’optimiseur “adam” qui est un choix pratique pour la plupart des tâches de classification en réseau de neurones. Le réseau est constitué d'un peu plus de 4000 paramètres.
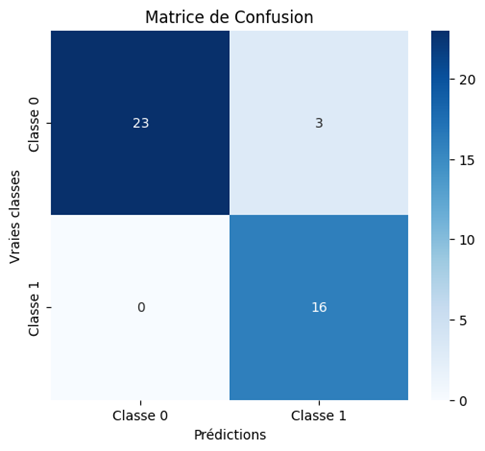
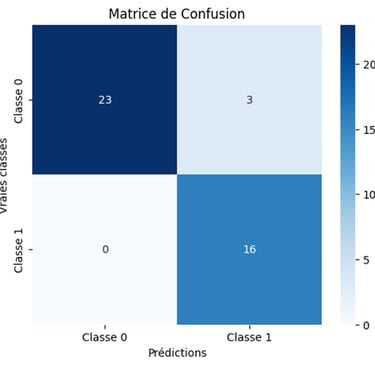
Voici la matrice de confusion du modèle présenté ici :
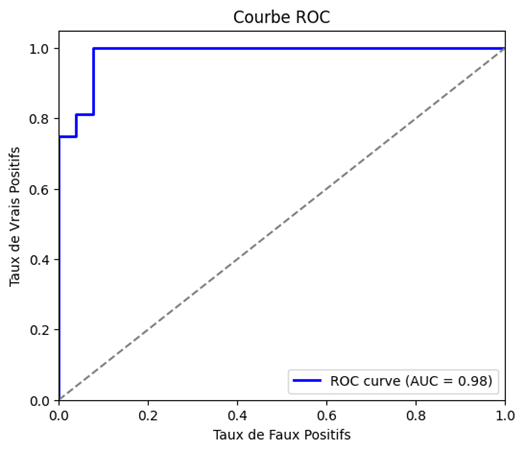
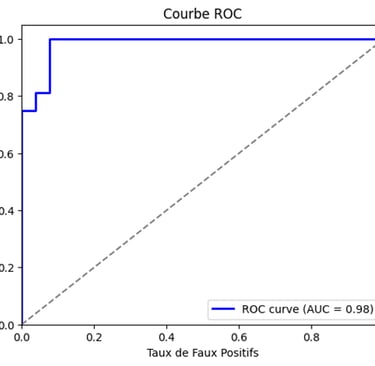
La courbe ROC trace le taux de vrais positifs (sensibilité) en fonction du taux de faux positifs pour différents seuils de classification.
L’axe des abscisses (x) représente le taux de faux positifs (FPR), c’est-à-dire la proportion d’éléments négatifs mal classés comme positifs.
L’axe des ordonnées (y) représente le taux de vrais positifs (TPR), aussi appelé sensibilité ou recall, qui correspond à la proportion d’éléments positifs correctement classés.
Un bon classificateur a une courbe, comme dans le cas présent, qui monte rapidement vers le coin supérieur gauche (valeurs élevées de vrais positifs avec un faible taux de faux positifs).
Déploiement sur l’ESP32 avec le framework Espressif
La principale difficulté lorsqu’on veut faire tourner un réseau de neurones sur un microcontrôleur concerne la limite des ressources (RAM, mémoire flash et puissance de calcul). Il est souvent nécessaire de réduire la taille du modèle (moins de neurones, architecture plus petite) et, dans l’idéal, de le quantifier (passer de poids en 32 bits flottants à 8 bits entiers) pour gagner en mémoire et en rapidité d’inférence. Ici il n'y a pas de précautions particulières à prendre car le réseau est vraiment petit.
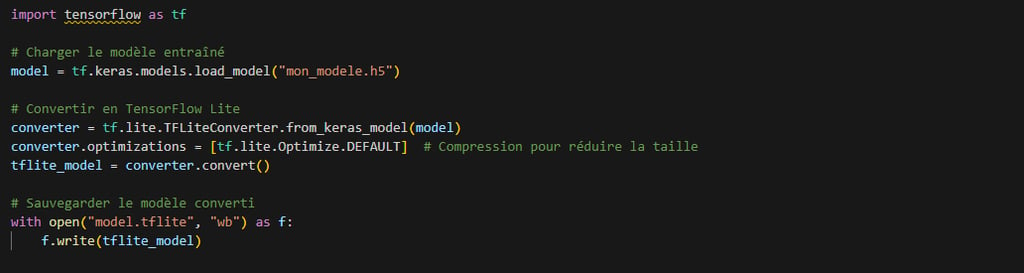
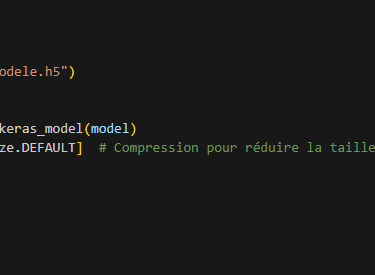
TensorFlow Lite Micro est généralement la solution la plus accessible pour convertir un modèle Keras en un format adapté, puis le déployer sur des plateformes embarquées comme l’ESP32. D’autres approches existent, mais le principe reste le même : on exporte un fichier contenant le réseau de neurones, puis on l’intègre au firmware de l’ESP32 en utilisant une bibliothèque adaptée.
Voici le code qui permet de convertir le modèle avec Tensorflow lite. On voit l’étape « d’optimisation »qui est en réalité l’étape de quantification du modèle :
Même un microcontrôleur relativement modeste, comme l’ESP32, peut effectuer de la classification en local. Le réseau léger comme celui-ci est caractérisé par un temps d’inférence très raisonnable (environ 0.22 ms par inférence).
On peut imaginer de nombreuses applications pratiques : détection d’anomalies dans des signaux capteurs (notamment en accéléromètrie), reconnaissance simple de sons ou d’images à basse résolution, déclenchement d’alarmes intelligentes, etc. Le fait de traiter les données directement dans le microcontrôleur permet des traitements « on the edge » et rend les systèmes beaucoup plus robustes et léger : il n’est plus nécessaire d’envoyer des informations sensibles à un serveur distant, de maintenir une connexion à un réseau centralisé, etc.
Si vous souhaitez reproduire cette intégration sur votre propre ESP32, vous pourrez consulter le dépôt GitHub associé à cet article (https://github.com/Bertrand-selvasystems/DeepLearning_ESP32_S3) pour voir comment importer le modèle, allouer les tenseurs, procéder à l’inférence et récupérer la prédiction finale. C'est une bonne base à répliquer ou à adapter pour d'autres applications.

Conclusion
Le dataset Sonar, avec ses 208 échantillons et ses 60 caractéristiques, constitue un bon cas d’étude pour démontrer la faisabilité d’une classification embarquée sur un microcontrôleur avec des temps d'inférence relativement rapide. En ajustant la taille du réseau et en appliquant des techniques d’optimisation comme la quantification, il est possible d’exécuter un modèle de Machine Learning directement sur l’ESP32, sans dépasser ses ressources limitées, même pour des modèles plus conséquent. On peut même envisager, pour des temps d'inférence de l'ordre de la seconde, des applications de computer vision sur l'ESP32.
Ce travail illustre surtout le potentiel des systèmes embarqués autonomes, capables d’effectuer des tâches d’intelligence artificielle sans dépendre d’une infrastructure cloud. Cette approche renforce la résilience des dispositifs en leur permettant d’opérer "off-grid", sans connexion permanente à un serveur distant. En traitant localement les données, un microcontrôleur comme l’ESP32 peut fonctionner de manière totalement autonome, prenant des décisions en temps réel et réagissant immédiatement aux variations de son environnement. Cela ouvre des perspectives intéressantes pour des applications où l’accès au réseau est limité, coûteux ou simplement indésirable, comme dans l’industrie, les environnements isolés ou les systèmes critiques.
Dans la continuité de cette expérimentation, je présenterai bientôt un dispositif appliqué à la maintenance prédictive, illustrant la robustesse et la pertinence de ces architectures autonomes. Ne disposant par moi-même, malheureusement, ni d’un sonar, ni de sous-marin, ce système reposera sur un banc expérimental équipé d’un moteur asynchrone alimenté par un variateur de vitesse, sur lequel il sera possible de générer des déséquilibres. L’ensemble sera surveillé par un boîtier autonome embarquant des accéléromètres et un ESP32, capable d’analyser les vibrations et d’anticiper les pannes potentielles sans nécessiter d’accès à un cloud ou une infrastructure extérieure : les spectrogrammes seront analysés par une réseau de neurone pour détecter les anomalies de fonctionnement.
Innovation
Systèmes embarqués, intelligence artificielle, deep learning, solutions sur mesure, efficacité, innovation, sécurité, fiabilité.
Contact
© 2025. All rights reserved.
© 2025. Tous droits réservés.